本文翻译自 We Built a Video Rendering Engine by Lying to the Browser About What Time It Is,原载于 Hacker News。
浏览器不想当摄像机
产品需求听起来很简单:把一个带动画的网页变成视频文件。
听起来很容易对吧?打开浏览器,录屏,导出 MP4,搞定。
我们试过。不行。
核心问题是:浏览器是实时系统。它们在能渲染的时候渲染,在负载高的时候跳帧,而且动画跟实际时间绑定。如果你的截图需要 200ms,但动画期望的是 16ms 一帧,结果就是一团卡顿的、无法观看的混乱。浏览器按自己的节奏渲染,我们按我们的节奏捕获——这两者永远无法达成一致。
我们需要更激进的方案。我们需要让浏览器相信:时间只在我们要它动的时候才动。
为什么不用 Remotion?
在深入之前,一个合理的问题:为什么要自己造轮子?Remotion 存在而且确实很棒。Remotion 优雅地解决了确定性渲染问题:一切都是由库控制的 React 组件,所以它确切知道你在哪一帧,可以按任意顺序渲染任意帧。这也解锁了跨多个浏览器标签页或机器的并行渲染,因为帧是独立的。
我们认真考虑过。但我们的用例有两个特殊约束:
第一,Replit 的视频渲染器接收一个 URL,输出一个 MP4。URL 指向的页面可能用 framer-motion、纯 CSS 动画、原生 <canvas>,或者某个冷门的 confetti 库。我们控制不了页面上有什么,只需要完美捕获它。Remotion 通过设计给你确定性,但要求你在它的组件框架内构建。我们需要的是从外部对任意网页内容施加确定性。
第二,我们的视频由 AI Agent 生成。把 Agent 限制在 Remotion 的组件模型里,意味着要教它一个库的惯用语,而不是让它使用整个 Web 平台。Agent 需要理解的框架表面积越少,输出质量越好。
所以:不用特殊框架,不买入库的账,只要一个 URL。这意味着要做那件难事:事后让任意浏览器环境变成确定性的。
冻结时间:虚拟时钟
我们视频渲染器的核心是一个 JavaScript 文件(撰写时约 1200 行),注入到我们捕获的每个页面。它的任务简单而大胆:用我们控制的假时钟替换浏览器里主要的时间相关 API。
我们替换了 setTimeout、setInterval、requestAnimationFrame、Date、Date.now() 和 performance.now()。实践中,这覆盖了大多数动画代码依赖的主要 JavaScript 时间原语。页面以为时间正常流逝,实际上,时间每帧只前进 1000/fps 毫秒,而且只在我们要它前进的时候。
这意味着一个实际渲染每帧需要 500ms 的 60fps 动画,仍然会产生丝般顺滑的 60fps 视频。页面永远不知道区别——从它的角度,每帧精确地需要 16.67ms,永远如此。
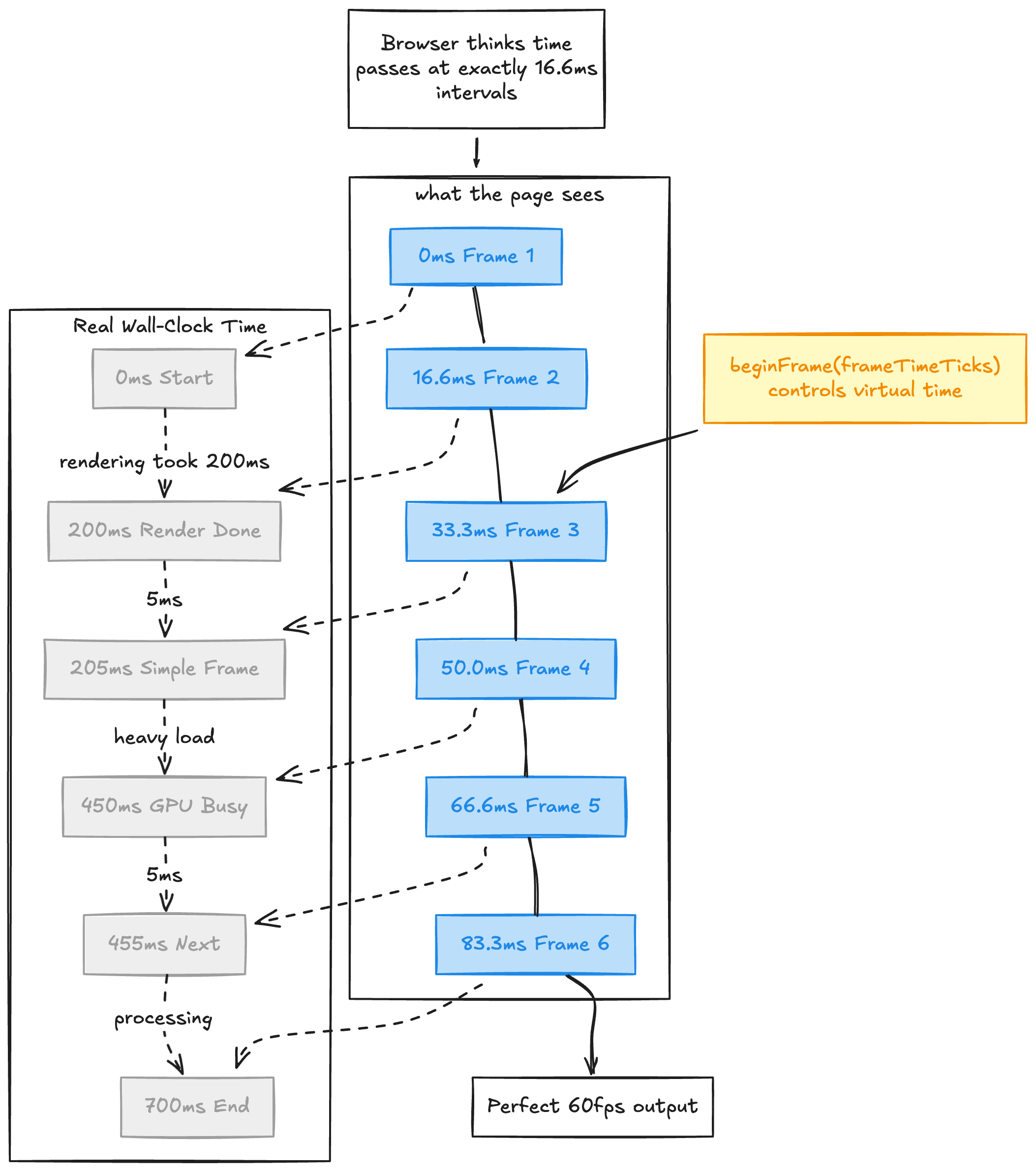
帧循环长这样:
nextFrame() {
const loop = async () => {
await seekCSSAnimations(currentTime); // 同步 CSS
await seekMedias(); // 同步视频
currentTime += frameInterval; // 滴答,时钟前进
callIntervalCallbacks(currentTime); // 触发 setInterval
callTimeoutCallbacks(currentTime); // 触发 setTimeout
callRAFCallbacks(currentTime); // 触发 rAF
await captureFrame(); // 截图
loop(); // 下一帧
};
loop();
}
推进时钟,触发回调,捕获,重复。每一帧都是确定性的,每次都一样。
个人感悟:这种”欺骗浏览器”的思路非常巧妙。与其改变应用代码来适应录制需求,不如改变运行环境让应用无感知。这让我想到了 React 的 Synthetic Events 或者 Node.js 的 vm 模块——通过在底层做手脚来获得上层的控制权。
合成器预热问题(或者:为什么要渲染不可见的帧)
开发过程中我们发现了一个有趣的 bug:如果加载页面和开始录制之间有任何延迟(我们在开始和结束时间触发 hook,只录制需要的部分),Chrome 的合成器会进入一个糟糕的状态。
根本原因?我们逐帧驱动 Chrome 的渲染循环,而不是让它自由渲染。如果一段时间没有发出帧请求,内部缓冲区就会过期。解决方案是一个预热循环,在等待页面发出准备好录制的信号期间,以约 30fps 持续发出”跳过帧”:
startWarmup() {
const warmupFrame = async () => {
if (startFlag) { stopWarmup(); return; }
await skipFrame();
warmupTimerId = setTimeout(warmupFrame, 33);
};
warmupFrame();
}
我们渲染了几十帧没人会看到的画面,只为了保持 Chrome 合成器不过期。
这是一个典型的分布式系统问题——当你接管了控制权,就要负责维护系统的”心跳”。浏览器的渲染管线不是为”暂停后恢复”设计的,你必须模拟持续的活动。
<video> 元素的传奇:五层变通方案
这里事情变得真正疯狂。在 headless 环境中,依赖浏览器原生的 <video> 播放路径对我们的用例来说是脆弱且通常不确定的。不同的编解码器/容器组合行为不同,而且我们仍然需要与虚拟时间绑定的帧级精准 seek。
我们的解决方案是一个让任何理智工程师都要哭出来的视频处理鲁布·戈德堡机械:
- 拦截:一个
MutationObserver监视 DOM 中的<video>元素 - 服务端预处理:检测到视频源时,页面 post 到一个内部端点 (
/__video_preprocess),Puppeteer 拦截它。然后我们在服务器上运行 FFmpeg,转码为分段 MP4(-movflags frag_keyframe+empty_moov+default_base_moof) - 浏览器内解复用:预处理后的视频字节返回给页面,mp4box.js 把它们解复用成编码的视频块
- 用 WebCodecs 解码(原生优先,polyfill 后备):通过
LibAVWebCodecs.getVideoDecoder(...)请求解码器,优先使用原生 WebCodecs,兼容时回退到基于 WASM 的 libav.js polyfill - 渲染到 canvas:原始
<video>元素在视觉上被替换为一个<canvas>,绘制与虚拟时钟同步的解码帧
分段 MP4 格式在这里很关键:它让 mp4box.js 可以增量解析,不需要先 seek 到文件末尾。解码使用 10 帧的前瞻窗口来保持低延迟而不爆内存:
const DECODE_LOOKAHEAD = 10;
feedChunksUpTo(targetIndex) {
const end = Math.min(targetIndex, this._chunks.length - 1);
for (let i = this._fedUpTo + 1; i <= end; i++) {
this.decoder.decode(chunk);
}
this._fedUpTo = Math.max(this._fedUpTo, end);
}
这段关于视频处理的描述堪称”硬核”。从 DOM 监听到 FFmpeg 转码、再到 WebCodecs 解码,整个链路的复杂度令人咋舌。但这就是处理”任意网页”的代价——你必须在每一条可能的路径上都做好 workaround。
音频:监听 Web Audio API
你无法可靠地从 headless 浏览器捕获音频输出。所以我们不尝试捕获扬声器输出,而是 监视播放意图。
我们 monkey-patch 了关键的 Web Audio API 和 HTMLMediaElement 入口点,在音频元数据到达扬声器路径之前就在源头拦截:
// 1. Patch fetch() 追踪 ArrayBuffer -> URL 映射
// 2. Patch XMLHttpRequest 处理 arraybuffer 响应
// 3. Patch decodeAudioData 映射 AudioBuffer -> 源 URL
// 4. Patch AudioNode.connect 构建连接图
// 5. Patch AudioBufferSourceNode.start 检测播放时机
// 6. Patch HTMLAudioElement.prototype.play 捕获 new Audio(url).play()
当页面播放声音时,我们现在知道:哪个音频文件、何时开始、多大声(通过遍历 GainNode 图)、以及是否循环。
这个方法覆盖了最常见的音频路径,设计上能跨 Howler.js(Gemini 不知为何喜欢用这个)、Tone.js、原生 Web Audio 和普通 <audio> 使用模式工作。已知有一些缺口——通过 OscillatorNode 程序化生成的音频、<video> 元素的音频、以及 AudioWorkletNode 处理都无法被这个方法捕获,因为它们不暴露可 fetch 的源 URL。AudioNode.connect 的 patch 充当部分安全网,因为所有音频节点必须经过连接图,但完全合成的音频仍然是一个限制。
然后我们在服务端下载原始音频文件,在第二次 FFmpeg pass 中,用 filter chain 把它们全部混合在一起,加上正确的时间、音量和淡入淡出效果:
Per track: [N] atrim -> aloop -> adelay -> volume -> afade -> [aN]
Final mix: [a0][a1]...[aN] amix=inputs=N:normalize=0
视频流是直接拷贝的(-c:v copy),不重新编码,而所有音频轨道被混合并封装进去。
仍有一些边缘情况。例如,blob: 和 data: 媒体 URL 被服务端预处理路径有意跳过,动态生成且从未暴露可 fetch URL 的媒体无法用这种方式重建。
音频的处理思路和视频类似:不尝试捕获”输出”,而是拦截”意图”。这是一个通用模式——当你无法控制源头时,在中间层做 interception 是最可靠的方案。
确定性是全职工作
你可能以为一旦控制了时间和渲染,就完成了。你还没有完成。浏览器有很多方式变得不确定。
比如 OffscreenCanvas,它让页面可以在 web worker 线程上渲染,绕过我们的主线程捕获管道。所以我们禁用它:
// deterministic-safety-shim.js
Object.defineProperty(window, 'OffscreenCanvas', { value: undefined, writable: false });
Object.defineProperty(
HTMLCanvasElement.prototype,
'transferControlToOffscreen',
{ value: undefined, writable: false }
);
由于我们在云基础设施的 headless 浏览器中渲染任意 URL,子资源请求会根据 SSRF 模式验证:云元数据端点、私有 IP、localhost 和内部主机名。对于服务端媒体获取,重定向目标也会重新验证(视频预处理跟随多次跳转;音频更保守)。
服务本身特意设计为单飞:应用中一次一个活跃渲染,并发设为 1。视频渲染非常消耗资源,隔离比吞吐量更重要:Chrome 使用数 GB 内存,FFmpeg 榨干 CPU,内存压力会导致帧损坏。
“确定性是全职工作”这句话道出了真谛。当你试图让一个本就是为实时交互设计的系统变得确定时,你需要考虑每一个可能的变数。这就像是在玩打地鼠——解决一个问题,又冒出三个。
站在巨人肩膀上:WebVideoCreator
我们没有从零开始。我们的渲染器深受 WebVideoCreator 启发,这是 Vinlic 的开源项目,率先提出了时间虚拟化 + BeginFrame 捕获在 headless Chrome 中的核心思想。那个项目值得真正的赞誉。你可以 monkey-patch 浏览器时间 API 并结合 Chrome 的确定性渲染模式逐帧捕获任意网页——这个根本性的洞察真的很聪明,没有它我们要花长得多的时间才能走到这一步。
我们分道扬镳的地方:WebVideoCreator 是针对旧的 headless 模式构建的,使用主 chrome 二进制。从那时起,Chrome 把旧的 headless 模式拆分成了单独的 chrome-headless-shell 二进制,有不同的 API 表面(从 Chrome 120 开始,在 Chrome 132 中完全从主二进制移除)。我们还需要与云基础设施(Cloud Run、GCS 上传、Datadog tracing)更紧密的集成,更严格的安全(渲染不可信 URL 的 SSRF 保护),以及对视频元素管道和音频提取更多控制。所以我们用 TypeScript 和现代 Puppeteer 重写了它,并为我们的部署模型调整了架构。
我们计划开源我们的实现。这里的技术(时间虚拟化、BeginFrame 捕获、视频元素变通管道)对任何从网页内容构建程序化视频的人都很有用,生态系统有更多选择会更好。敬请期待。
如果你对确定性浏览器捕获、底层 Chrome API、以及让 FFmpeg 做有趣的事情感兴趣,我们在招聘。
核心要点
-
时间虚拟化是关键:通过替换浏览器的时间 API,可以让任何动画变得确定性,无论它用什么框架实现。
-
不要捕获输出,拦截意图:对于音频这类难以从输出端捕获的内容,在 API 层面拦截调用是更可靠的方案。
-
Headless Chrome 有很多坑:从合成器预热到视频元素处理,每一步都需要 workaround。
-
确定性需要全面考虑:OffscreenCanvas、SSRF 防护、资源隔离——任何一个细节都可能导致失败。
-
站在开源的肩膀上:WebVideoCreator 的核心思想为这个项目奠定了基础,开源社区的智慧值得善用。
这种”欺骗浏览器”的技术思路不仅适用于视频渲染,对于自动化测试、网页归档、甚至爬虫都有借鉴意义。核心思想是:与其改变应用来适应环境,不如改变环境来适应应用。