本文翻译自 The Linker,原载于 Hacker News。
引言
在上一篇文章中,我们见证了编译器如何将优化后的 SSA(Static Single Assignment)转换为机器码字节,并打包成目标文件。每个 .o 文件包含一个包的编译后代码——包括机器指令、符号定义,以及标记需要修正地址的重定位信息。
但你的程序不仅仅是一个包。即使是一个简单的 “hello world” 程序也会导入 fmt,而 fmt 又导入了 io、os、reflect 等几十个包。每个包都被单独编译成自己的目标文件。这些文件都无法独立运行。
这就是链接器(linker)发挥作用的地方。链接器的任务是将所有这些分散的目标文件合并成一个操作系统可以运行的可执行文件。
让我们来看看链接器做了什么以及它是如何工作的。
链接器的四大核心任务
从高层次来看,链接器执行四个主要任务:
1. 符号解析(Symbol Resolution):你的代码调用 fmt.Println,但该函数定义在不同的目标文件中。链接器找到所有这些跨文件引用并将它们连接起来。
2. 重定位(Relocation):还记得机器码中的那些占位符地址吗?现在链接器知道所有内容在内存中的位置了,它会用实际地址来修补这些占位符。
3. 死代码消除(Dead Code Elimination):如果你导入一个包但只使用其中一个函数,链接器会移除所有未使用的函数。这使你的二进制文件保持小巧。
4. 布局和可执行文件生成(Layout and Executable Generation):链接器决定代码和数据在内存中的位置,然后按照操作系统期望的格式(Linux 上的 ELF、macOS 上的 Mach-O、Windows 上的 PE)输出可执行文件。
让我们依次深入了解这些步骤,首先从链接器如何确定存在哪些符号以及它们在哪里开始。
符号解析
每个目标文件都包含符号(symbols)——标识函数、全局变量和其他程序元素的名称。有些符号在文件中被定义(实际的代码或数据在那里),而其他的只是被引用(代码使用它们,但它们在别处)。
举个例子:
// main.go
package main
import "fmt"
func main() {
fmt.Println("Hello")
}
编译后,你的 main.o 包含 main.main——这是你的函数,包含完整的机器码。但它也引用了 fmt.Println,而那段代码不在这里,只是一个指向别处的名称。
注意: 在实践中,
fmt.Println会被编译器内联,所以在这种情况下没有实际的跨包引用。但对于不被内联的函数,这个概念是成立的。
在 fmt.o 中,你会找到实际的 fmt.Println 实现。但该文件引用了 io.Writer、os.Stdout 以及来自其他包的更多符号。
每个包都定义一些符号并引用其他符号。链接器需要将所有这些引用与它们的定义匹配起来。为此,它首先需要构建一个关于存在什么的完整图景。
加载器(Loader):构建全局符号索引
在链接器能做任何有用的事情之前,它需要了解程序中的每个符号。这是加载器(Loader)的工作(代码位于 src/cmd/link/internal/loader/)。
加载器读取目标文件并构建所有符号的统一索引。它从你的 main 包开始,读取该目标文件,发现其导入。你的代码使用了 fmt,所以现在需要加载 fmt。而 fmt 导入了 io、os、reflect 等。加载器持续跟踪导入,直到找到程序依赖的每个包。runtime 包也总是会被加载,因为每个 Go 程序都需要它。
在读取每个文件时,加载器记录每个符号并将引用连接到定义。当代码调用另一个包的函数时,目标文件只是说”我需要这个符号”。加载器查找它并记录它指向哪里。大多数符号通过名称识别,但有些——比如字符串字面量——是内容可寻址的(content-addressable),通过其内容的哈希值识别。如果两个包都使用 "Hello",它们会产生相同的哈希值,并在最终二进制文件中共享一个副本。
索引本身很简单。每个符号获得一个唯一的整数 ID。加载器维护几个关键数据结构:从符号 ID 到其位置的映射(哪个目标文件、该文件内的哪个本地索引),从名称如 fmt.Println 到其 ID 的查找表,以及用于存储”这个符号是否可达?”等属性的空间(稍后填充)。实际的代码和数据字节保留在目标文件中——加载器只记录在哪里找到它们。
最终,加载器有了完整的图景:每个符号都被索引,每个引用都被解析。你可以在 src/cmd/link/internal/loader/loader.go 中找到加载逻辑。
但是,索引了所有内容并不意味着我们需要所有内容。是时候削减脂肪了。
死代码消除
加载器索引了来自每个包的每个符号,但你可能不会全部使用。如果你导入 fmt 只是为了调用 Println,你不需要那个包里的几十个其他函数。
链接器通过死代码消除来解决这个问题。从 main.main 开始,它追踪每个函数调用和每个全局变量访问,设置我们之前提到的”这个符号是否可达?”属性。完成后,任何未被标记的东西都会被丢弃。如果你导入了一个有五十个函数的包但只调用了一个,其他四十九个就会消失。
这就是为什么 Go 二进制文件尽管采用静态链接仍能保持相对较小的原因。你可以在 src/cmd/link/internal/ld/deadcode.go 中找到这个逻辑。
符号解析完成、死代码消除后,链接器确切知道需要放入最终二进制文件的内容。但有一个问题:机器码对于其他包中的符号仍然有占位符地址。
重定位(Relocation)
当编译器为一个包生成机器码时,它知道该包内的符号,但不知道在其他地方定义的符号。对另一个包中函数的每次调用,对导入模块中变量的每次引用——这些都只是占位符,说”稍后填这个”。链接器现在的工作是弄清楚所有这些跨包符号实际去哪里,然后用真实地址修补这些占位符。
这造成了一个鸡生蛋还是蛋生鸡的情况:你不能在知道所有东西在哪里之前填入地址,但你需要先布局所有代码和数据才能知道所有东西在哪里。链接器分两遍解决这个问题:先给所有东西分配地址,然后回去修补代码。
地址分配
链接器根据每个符号包含的内容及其使用方式将内存组织成段(sections):
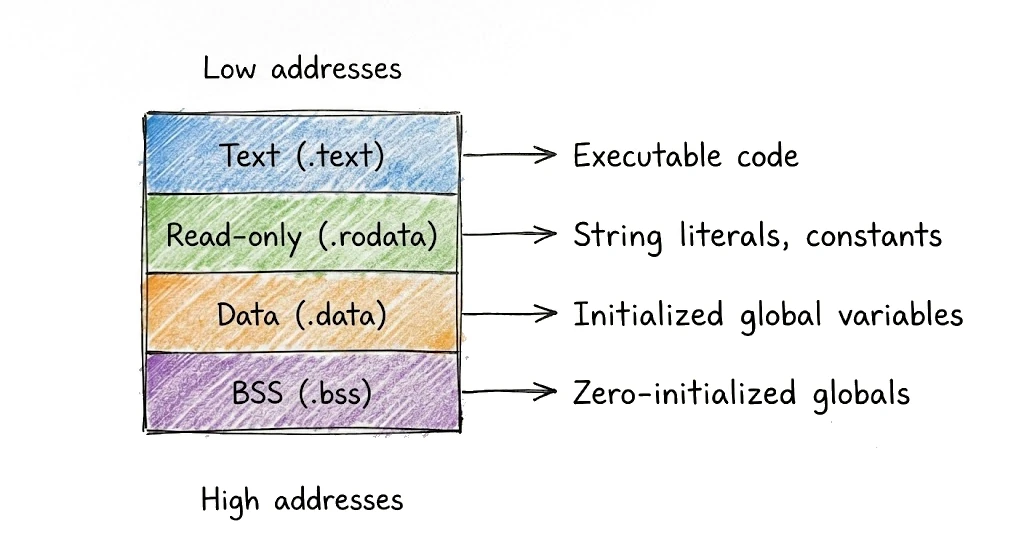
链接器逐个处理符号,将每个符号放置在其段的下一个可用地址处。函数会对齐到适当的边界(根据架构通常是 16 或 32 字节)以提高缓存效率。只读数据被分组在一起,以便可以被保护免受修改。.bss 段很特殊——它在文件中不占空间,因为那里的所有东西都只是零,但操作系统在程序加载时会分配内存。在这个阶段结束时,每个符号都有了具体的地址。
现在所有东西都有了地址,是时候修复所有那些占位符了。
修补重定位
每个占位符都有一个关联的重定位记录,说明应该在那里填入哪个符号的地址。链接器遍历每个重定位,查找目标地址,并将其修补进去。对于函数调用,CPU 期望一个相对偏移量(”向前跳 500 字节”),所以链接器计算调用点和目标之间的距离。对于全局变量引用,它直接写入绝对地址。当这一遍完成时,机器码就完成了——每个占位符都被真实地址替换。
链接器现在有了完全链接的机器码。剩下的就是将其打包成操作系统实际可以运行的文件。
生成可执行文件
最后,链接器将所有内容组织成段(sections),将它们分组为段(segments),并写入可执行文件。让我们看看这种组织是如何工作的。
Sections
链接器根据符号是什么以及如何使用将它们分组到sections:
.text存放可执行代码——你的函数,标记为可读可执行.rodata存放只读数据——字符串字面量、常量、类型描述符.data存放已初始化的全局变量——可读可写.bss存放零初始化的全局变量——可读可写,但在文件中不占空间.noptrdata和.noptrbss存放垃圾收集器可以忽略的数据(没有指针)
Go 还为运行时元数据生成特殊的段。.gopclntab 段包含 PC-line 表——从程序计数器值到源文件和行号的映射,这使得堆栈跟踪工作并启用反射。
但 sections 是链接器的内部组织。操作系统以段(segments)的方式思考。
Segments
Sections 被分组为segments用于加载。Sections 是链接器的数据视图,segments 是操作系统加载器的视图。操作系统不关心单个 sections;它以正确的权限将整个 segments 映射到内存中。
一个典型的 Go 可执行文件有一个 text 段(代码 + 只读数据,映射为可读可执行)和一个 data 段(可写数据 + BSS,映射为可读可写)。在某些平台上,它们之间还有一个单独的只读数据段用于 .rodata。
段布局对安全性很重要。现代系统使用 W^X(write xor execute)——内存可以是可写的或可执行的,但不能两者兼有。通过将代码和数据分离到具有不同权限的不同段中,链接器启用了这种保护。
段定义好后,链接器以操作系统理解的格式将所有内容写入磁盘。
文件格式和加载
不同的操作系统使用不同的可执行格式——Linux 使用 ELF,macOS 使用 Mach-O,Windows 使用 PE。尽管有差异,它们都包含:
- 一个头部标识文件格式和架构
- 程序头(或等效物)描述要加载的段
- 节头描述内容供调试器和工具使用
- 实际的代码和数据字节
- 可选的调试信息(DWARF 格式)
一个有趣的细节:头部指定了一个入口点——操作系统开始执行的地方——它不是你的 main 函数。它是 Go 运行时启动代码,如 _rt0_amd64_linux,它设置栈、初始化内存分配器、启动垃圾收集器并启动调度器,最后才调用你的 main.main。
你可以在 src/cmd/link/internal/ld/elf.go 和其他格式的类似文件中找到输出代码。如果你想更详细地探索 Go 二进制文件的最终结构,请查看我在 GopherCon UK 的演讲 Deep dive into a Go binary。
到目前为止我们讨论的所有内容都假设了默认情况:一个捆绑了所有内容的独立可执行文件。但链接器也可以产生其他类型的输出。
静态链接、动态链接和构建模式
Go 偏好静态链接——将所有内容捆绑成一个独立的二进制文件。Go 运行时、标准库、所有依赖项:它们都被编译进去。没有外部依赖意味着你可以将二进制文件复制到另一台机器上,它就能直接运行。
当你使用 cgo 时,Go 必须动态链接到系统库如 libc。链接器添加一个 .dynamic 段,包含符号表、库名和重定位条目。它还指定一个解释器——动态链接器的路径(Linux 上是 /lib64/ld-linux-x86-64.so.2)。当你运行程序时,内核首先加载动态链接器,它在跳转到你的代码之前解析外部符号并加载共享库。
使用 -buildmode 标志,链接器可以产生其他输出类型:C 兼容的静态库(c-archive)、共享库(c-shared)或 Go 插件(plugin)。每种模式都会改变导出什么、运行时如何初始化以及写入什么文件格式。
现在我们已经看到了所有组成部分,让我们看一个具体的例子来观察它们如何协同工作。
完整示例演练
让我们通过整个链接过程跟踪一个有两个包的简单程序。
main.go:
package main
import "example/greeter"
func main() {
greeter.Hello()
}
greeter/greeter.go:
package greeter
import "fmt"
//go:noinline
func Hello() {
fmt.Println("Hello")
}
注意:
//go:noinline指令防止编译器将Hello内联到main.main中。没有它,编译器会内联函数,链接器就没有跨包调用需要解析了。
让我们跟随这个程序经历链接的每个阶段。
编译后
编译器生成独立的目标文件。main.o 包含 main.main 并有对 example/greeter.Hello 的引用——它调用那个函数但没有代码。有一个重定位标记调用地址需要填入的位置。
greeter.o 包含 example/greeter.Hello,它反过来引用 fmt.Fprintln(这是 fmt.Println 内部调用的)。而 fmt.a(fmt 包的归档文件)有实际的实现,以及对 io.Writer、os.Stdout 等的引用。
链接器首先加载所有这些部分并弄清楚它们是什么。
加载和解析
链接器加载所有这些文件并构建符号表。注意符号名称包含完整的模块路径:
Symbol Table:
main.main → defined in main.o
example/greeter.Hello → defined in greeter.o
fmt.Fprintln → defined in fmt.a
(plus hundreds more from runtime and std library)
每个引用都可以匹配到一个定义。如果有缺失的东西,链接器会在这里停止并报未定义符号错误。
接下来,链接器弄清楚实际使用了什么。
死代码消除
从 main.main 开始,链接器追踪所有调用:
main.main → calls example/greeter.Hello
example/greeter.Hello → calls fmt.Fprintln
fmt.Fprintln → calls io.Writer methods, uses os.Stdout
...
这个链中的所有东西都被标记为可达。任何不在链中的东西——你导入但从未实际使用的包中的函数——被丢弃。
确定了可达符号集合后,链接器为每个符号分配一个地址。
分配地址
现在链接器在内存中布局所有可达符号。这是我们例子的样子(来自实际构建的地址):
Text section (starting at 0x401000):
0x46f1e0: _rt0_amd64_linux (entry point)
0x439040: runtime.main
0x491b20: main.main
0x491ac0: example/greeter.Hello
0x48cac0: fmt.Fprintln
...
Data section (starting at 0x554000):
0x55e148: os.Stdout
...
现在链接器可以修补机器码中的所有占位符地址。
修补重定位
地址分配好后,链接器回去填入所有占位符。
在 main.main 中,有一个对 example/greeter.Hello 的调用。我们可以在反汇编中看到它:
TEXT main.main(SB)
0x491b20 CMPQ SP, 0x10(R14)
0x491b24 JBE 0x491b31
0x491b26 PUSHQ BP
0x491b27 MOVQ SP, BP
0x491b2a CALL example/greeter.Hello(SB) ← patched with offset to 0x491ac0
0x491b2f POPQ BP
0x491b30 RET
0x491b2a 处的 CALL 指令包含一个相对偏移量,跳转到 0x491ac0 处的 example/greeter.Hello。从 greeter.Hello 到 fmt.Fprintln 的调用也是一样——链接器计算偏移量并修补进去。
现在所有的跳转和调用都指向正确的位置。
剩下的就是写入最终文件。
写入可执行文件
最后,链接器将所有内容写出。在 Linux 上,我们可以用 readelf 检查结果(在 macOS 上,使用 otool -h):
$ readelf -h ./example
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Entry point address: 0x46f1e0
Number of program headers: 6
Number of section headers: 25
...
就是它——一个完整的、独立的可执行文件。入口点 0x46f1e0 是 _rt0_amd64_linux,这是运行时启动代码,最终会调用我们的 main.main。
如果你想在自己的代码上看到这种情况发生,有一些有用的命令可以探索。
动手试试
如果你想窥探幕后,有一些命令可以让你看到链接器在做什么。
要观察链接器工作,通过 ldflags 传递 -v:
$ go build -ldflags="-v" .
# example
build mode: exe, symbol table: on, DWARF: on
HEADER = -H5 -T0x401000 -R0x1000
107437 symbols, 20441 reachable
48122 package symbols, 39987 hashed symbols, 14790 non-package symbols, 4538 external symbols
112153 liveness data
你会看到加载了多少符号,死代码消除后有多少可达,以及其他构建信息。
一旦你有了二进制文件,你可以用 nm 检查它的符号表:
go tool nm ./example | less
这会转储可执行文件中的每个符号及其地址。输出很多——即使是我们简单的程序也有来自运行时的超过 2000 个符号。
要查看段在内存中如何布局,使用你平台的二进制检查工具:
readelf -S ./example # Linux
otool -l ./example # macOS
如果你想看到整个构建过程,包括确切的链接命令:
go clean && go build -x .
go clean 确保你得到完整的输出——没有它,缓存构建可能会跳过步骤。
这会打印 go 工具运行的每个命令。你会看到编译器调用,然后是带有所有标志的链接器调用。这是理解 go build 下面发生了什么的好方法。
总结
链接器是编译过程的最后一步。它接受单独的目标文件并将它们组合成一个可执行文件:
- 符号解析:Loader 构建程序中每个符号的全局索引,递归跟踪导入并将引用连接到定义。内容可寻址的符号允许相同的数据(如字符串字面量)跨包共享。
- 死代码消除:从
main.main开始,链接器跟踪可达性并删除所有未使用的东西。这就是为什么 Go 二进制文件尽管采用静态链接但仍保持相当小的原因。 - 重定位:链接器为每个符号分配一个具体地址,将它们组织成段(
.text、.rodata、.data、.bss),然后修补机器码中的所有占位符地址。 - 可执行文件生成:Sections 被分组为具有适当权限(W^X)的 segments,链接器以特定于操作系统的格式(ELF、Mach-O、PE)写出所有内容。入口点不是你的
main——它是运行时启动代码,在调用你的代码之前初始化 Go 运行时。
Go 的链接器还处理不同的构建模式——从默认的静态链接可执行文件到 C 归档、共享库和插件。
如果你想更深入地了解链接器,探索 src/cmd/link/internal/ld/。代码有很好的文档,看看一个真正的生产链接器是如何工作的是令人着迷的。
就这样,我们完成了通过 Go 编译器的旅程!从源代码通过扫描、解析、类型检查、IR 优化、SSA 转换、代码生成,最后到链接——你的 Go 程序现在是一个准备运行的独立可执行文件。
但故事并没有在这里结束。那个可执行文件包含 Go 运行时:管理 goroutine 的调度器、回收内存的垃圾回收器、内存分配器,以及使 Go 的并发模型工作所有机制。在下一个系列中,我们将探索运行时如何使你的程序生动起来。敬请期待!
个人总结
这篇文章深入浅出地介绍了 Go 链接器的工作原理,让我对 Go 编译流程的最后一步有了清晰的认识。几个关键要点:
-
静态链接的优势:Go 默认采用静态链接,这意味着生成的二进制文件是自包含的,部署时无需担心依赖问题。这是 Go 在云原生时代如此流行的原因之一。
-
死代码消除的精妙:通过从
main.main开始跟踪可达性,链接器能够大幅减小二进制文件的体积。这解决了静态链接可能导致文件过大的潜在问题。 -
内存布局的安全性考虑:通过 W^X(写或执行)保护,代码和数据被分离到不同的段中,这增强了程序的安全性,防止了代码注入攻击。
-
运行时启动的重要性:程序的入口点不是我们的
main函数,而是运行时启动代码。这提醒我们 Go 程序背后有一个复杂的运行时在支撑。
对于想要深入理解 Go 内部机制的开发者来说,这篇文章是很好的起点。建议实际运行文中提供的命令(如 go build -ldflags="-v"、go tool nm),亲手探索链接器的输出会更有收获。