本文翻译自 Data Engineering for Large Models: Architecture, Algorithms & Projects,原载于 Hacker News。
引言
“数据是新时代的石油,但前提是你得懂得如何提炼它。”
在大模型时代,数据质量决定了模型性能的上限。然而,关于 LLM 数据工程的系统化资源仍然极其稀缺——大多数团队仍在通过试错法摸索前进。
这本书旨在填补这一空白。它系统性地覆盖了从 预训练数据清洗 到 多模态对齐,从 RAG 检索增强 到 合成数据生成 的完整技术栈,包括:
- 预训练数据工程:从 Common Crawl 等海量噪声数据源中提取高质量语料
- 多模态数据处理:图文对、视频、音频数据的收集、清洗和对齐
- 对齐数据构建:SFT 指令数据、RLHF 偏好数据、CoT 推理数据的自动化生成
- RAG 数据管道:企业级文档解析、语义分块和多模态检索
除了深入的理论讲解,书中还包含 5 个端到端的实战项目,提供可运行的代码和详细的架构设计。
在线阅读:https://datascale-ai.github.io/data_engineering_book/en/
书籍架构
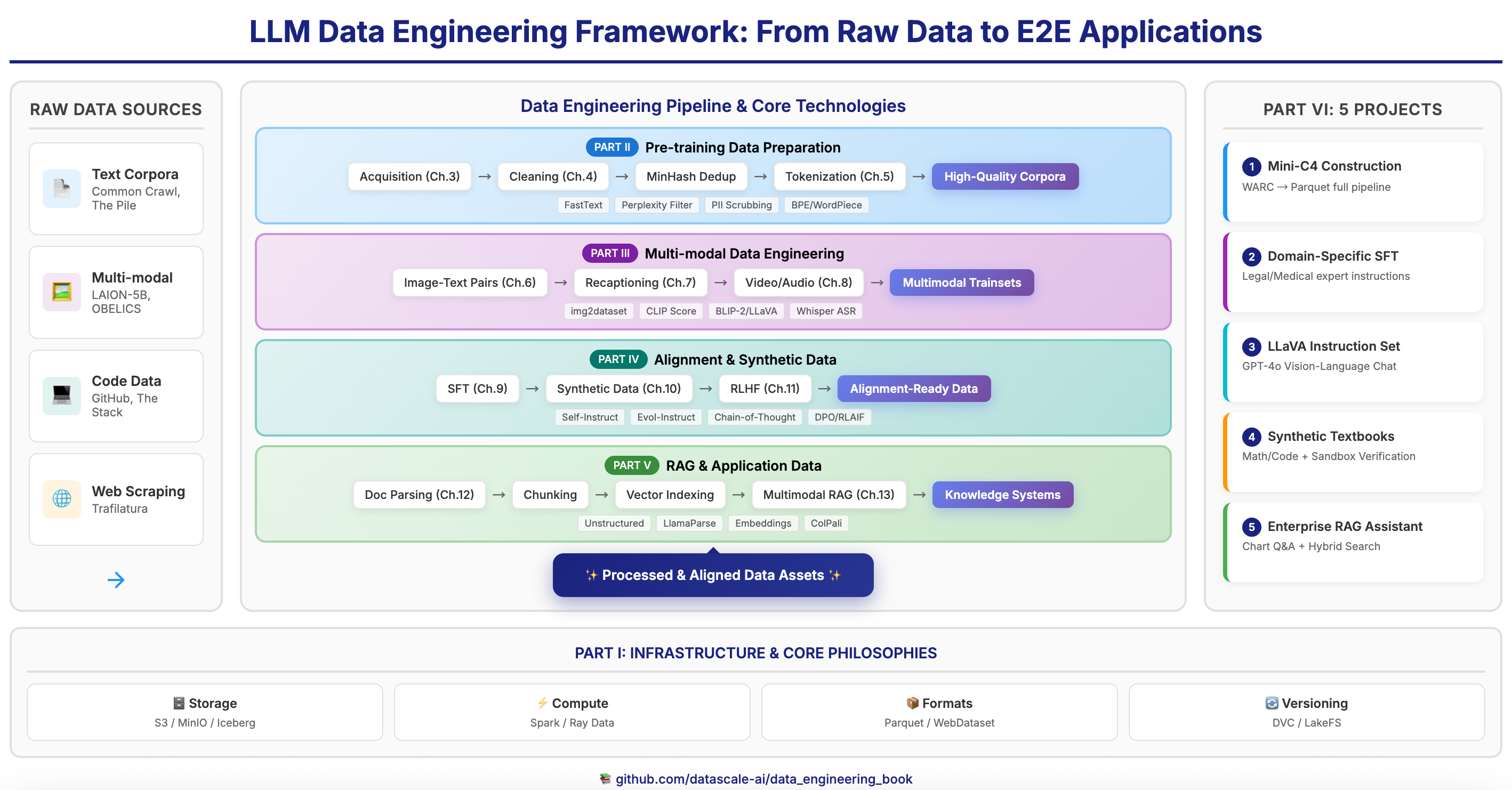
从原始数据到端到端应用的完整数据工程管道
目录概览
📖 6 大部分,13 章 + 5 个实战项目
│
├── 第一部分:基础设施与核心概念
│ ├── 第 1 章:LLM 时代的数据革命
│ └── 第 2 章:数据基础设施选型
│
├── 第二部分:文本预训练数据工程
│ ├── 第 3 章:数据采集
│ ├── 第 4 章:清洗与去重
│ └── 第 5 章:分词与序列化
│
├── 第三部分:多模态数据工程
│ ├── 第 6 章:图文对处理
│ ├── 第 7 章:重标注(Recaptioning)
│ └── 第 8 章:视频与音频数据
│
├── 第四部分:对齐与合成数据工程
│ ├── 第 9 章:指令微调数据
│ ├── 第 10 章:合成数据
│ └── 第 11 章:人类偏好数据
│
├── 第五部分:应用层数据工程
│ ├── 第 12 章:RAG 数据管道
│ └── 第 13 章:多模态 RAG
│
└── 第六部分:实战项目
├── 项目 1:构建 Mini-C4 预训练集
├── 项目 2:领域专家 SFT(法律)
├── 项目 3:构建 LLaVA 多模态指令集
├── 项目 4:合成数学/代码教科书
└── 项目 5:多模态 RAG 财报助手
核心亮点
全面系统的理论体系
- 贯穿始终的 Data-Centric AI 哲学
- 覆盖 LLM 数据全生命周期:预训练 → 微调 → RLHF → RAG
- 深入讲解 Scaling Laws(缩放定律)、数据质量评估、多模态对齐等主题
现代化的技术栈
| 领域 | 技术选型 |
|---|---|
| 分布式计算 | Ray Data, Spark |
| 数据存储 | Parquet, WebDataset, 向量数据库 |
| 文本处理 | Trafilatura, KenLM, MinHash LSH |
| 多模态 | CLIP, ColPali, img2dataset |
| 数据版本管理 | DVC, LakeFS |
丰富的实战项目
| 项目 | 核心技术 | 产出物 |
|---|---|---|
| Mini-C4 预训练集 | Trafilatura + Ray + MinHash | 高质量文本语料 |
| 法律专家 SFT | Self-Instruct + CoT | 领域指令数据集 |
| LLaVA 多模态 | Bbox 对齐 + 多图交错 | 视觉指令数据集 |
| 数学教科书 | Evol-Instruct + 沙箱验证 | PoT 推理数据集 |
| 财报 RAG | ColPali + Qwen-VL | 多模态问答系统 |
实战项目详解
让我重点介绍几个笔者认为最有价值的项目:
项目 1:构建 Mini-C4 预训练集
这个项目教你如何从零开始构建一个小型但高质量的预训练数据集。关键步骤包括:
- 使用 Trafilatura 从网页提取正文内容
- 用 Ray Data 进行分布式处理
- MinHash LSH 进行模糊去重
- KenLM 语言模型过滤低质量文本
项目 3:LLaVA 多模态指令集
LLaVA 是多模态大模型的代表作品。这个项目揭示了其数据构建的秘密:
- 如何进行边界框(Bounding Box)对齐
- 多图交错(Multi-image Interleaving)技术
- 从纯文本指令到视觉指令的转换方法
项目 5:多模态 RAG 财报助手
企业级 RAG 系统的典型案例:
- 使用 ColPali 进行文档级视觉检索
- Qwen-VL 处理表格和图表
- 构建端到端的多模态问答系统
本地开发
如果你想为这本书贡献内容,或者在本地预览:
# 克隆仓库
git clone https://github.com/datascale-ai/data_engineering_book.git
cd data_engineering_book
# 安装依赖
pip install mkdocs-material mkdocs-glightbox pymdown-extensions "mkdocs-static-i18n[material]"
# 本地预览
mkdocs serve
访问 http://127.0.0.1:8000 即可预览(支持中英文切换)。
目标读者
这本书适合以下人群:
- LLM 研发工程师:想深入了解数据对模型性能的影响
- 数据工程师 / MLOps 工程师:需要构建大规模数据处理管道
- 技术型 AI 产品经理:理解数据工程的产品化落地
- 研究人员:对 LLM 数据管道感兴趣
为什么这本书值得关注?
在 LLM 领域,大家往往关注模型架构和训练技巧,却忽略了数据工程的系统化建设。这本书的独特价值在于:
- 系统性:不是零散的博客文章,而是完整的数据工程体系
- 实用性:每个章节都配有可运行的代码
- 前瞻性:涵盖多模态、合成数据等前沿话题
- 开源性:完全免费,支持社区贡献
个人感悟
作为一个在 LLM 领域摸爬滚打的工程师,我深有体会:数据质量往往比模型架构更重要。很多时候,我们花大量时间调参、换模型,却忽略了最基础的数据清洗和对齐工作。
这本书最大的价值在于,它把”数据是新时代的石油”这句话从口号变成了可操作的技术路线。无论你是刚入门的新手,还是经验丰富的老手,都能从中找到有价值的内容。
特别推荐第四部分关于合成数据的章节——在高质量标注数据越来越稀缺的今天,如何用 AI 生成 AI 训练数据,是一个非常有前景的方向。
总结
《大模型数据工程》是一本填补行业空白的实用指南。它系统性地回答了一个关键问题:如何为 LLM 构建、清洗、对齐和管理数据?
关键要点:
- 数据质量是 LLM 性能的上限,值得投入与模型架构同等甚至更多的精力
- 数据工程不是一次性的工作,而是贯穿 LLM 全生命周期的持续过程
- 多模态和合成数据是未来两个重要方向
- 实战项目是理解理论的最佳方式
如果你正在从事 LLM 相关工作,强烈建议收藏这本书,并在实际项目中尝试其中的技术方案。
如果觉得这本书有帮助,请给个 Star! ⭐
GitHub: https://github.com/datascale-ai/data_engineering_book