本文翻译自 microgpt,原载于 Hacker News。
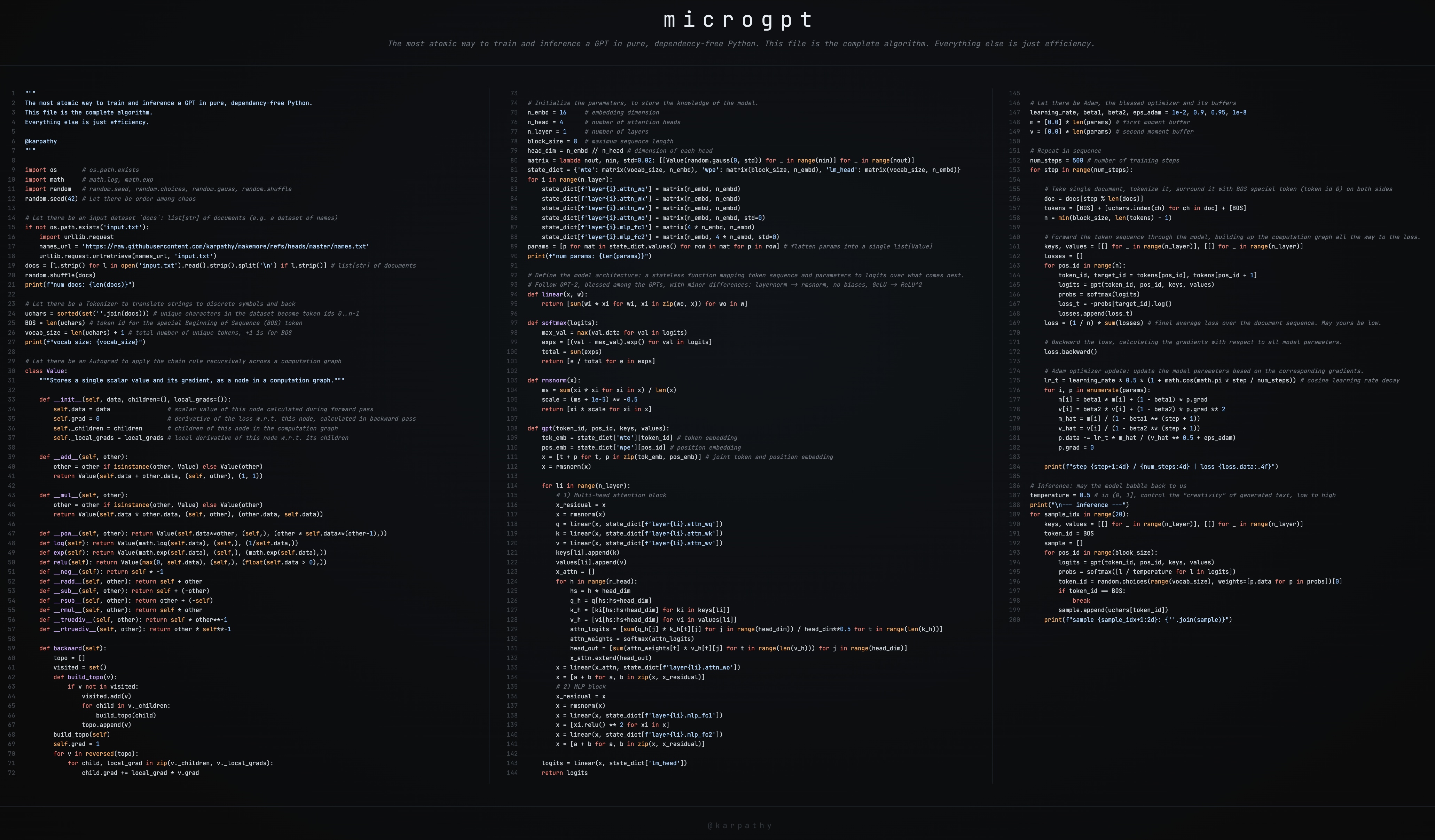
这是我的新艺术项目 microgpt 的简要指南——一个 200 行纯 Python、无任何依赖 的单文件,可以训练和推理一个 GPT。
这个文件包含了所需的所有算法内容:文档数据集、分词器(Tokenizer)、自动求导引擎(Autograd)、类似 GPT-2 的神经网络架构、Adam 优化器、训练循环和推理循环。其他所有东西都只是为了效率。我无法再简化它了。
这个脚本是我多个项目(micrograd、makemore、nanogpt 等)的结晶,也是我十年来将 LLM 简化到最本质的执念成果。我觉得它很美 🥹。它甚至可以完美地分成三列显示:
资源链接:
- GitHub Gist 完整源码:microgpt.py
- 网页版
- Google Colab 笔记本
以下是我带领感兴趣的读者逐步理解代码的指南。
数据集(Dataset)
大语言模型的燃料是文本数据流,可选地分成一组文档。在生产级应用中,每个文档可能是一个网页,但对于 microgpt,我们使用一个更简单的例子:32,000 个名字,每行一个:
# 创建输入数据集 `docs`:文档列表(例如名字数据集)
if not os.path.exists('input.txt'):
import urllib.request
names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt'
urllib.request.urlretrieve(names_url, 'input.txt')
docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()]
random.shuffle(docs)
print(f"num docs: {len(docs)}")
数据集长这样,每个名字是一个文档:
emma
olivia
ava
isabella
sophia
charlotte
mia
amelia
harper
... (后续约 32,000 个名字)
模型的目标是学习数据中的模式,然后生成类似的新文档。作为预告,到脚本结束时,我们的模型将生成(”幻觉”!)新的、听起来合理的名字:
sample 1: kamon
sample 2: ann
sample 3: karai
sample 4: jaire
sample 5: vialan
sample 6: karia
sample 7: yeran
sample 8: anna
sample 9: areli
sample 10: kaina
看起来不多,但从 ChatGPT 这样的模型角度来看,你与它的对话只是一个看起来很奇怪的”文档”。当你用提示词初始化文档时,从模型的角度来看,它的响应只是统计意义上的文档补全。
分词器(Tokenizer)
在底层,神经网络处理的是数字,不是字符,所以我们需要一种方法将文本转换为整数 token ID 序列,然后再转回来。生产级分词器如 tiktoken(GPT-4 使用的)基于字符块操作以提高效率,但最简单的分词器就是为数据集中的每个唯一字符分配一个整数:
# 创建分词器,将字符串转换为离散符号并转回
uchars = sorted(set(''.join(docs))) # 数据集中的唯一字符变成 token id 0..n-1
BOS = len(uchars) # 特殊的序列开始(BOS)token 的 id
vocab_size = len(uchars) + 1 # 唯一 token 总数,+1 是给 BOS
print(f"vocab size: {vocab_size}")
在上面的代码中,我们收集数据集中所有唯一字符(就是所有小写字母 a-z),排序后,每个字母根据其索引获得一个 ID。注意整数值本身没有任何意义;每个 token 只是一个独立的离散符号。除了 0、1、2,它们也可以是不同的 emoji。
此外,我们创建了一个特殊 token BOS(Beginning of Sequence),它作为分隔符:告诉模型”一个新文档在这里开始/结束”。稍后在训练时,每个文档两边都会被 BOS 包裹:[BOS, e, m, m, a, BOS]。模型学习到 BOS 开始一个新名字,另一个 BOS 结束它。因此,我们最终有 27 个词汇(26 个可能的小写字母 a-z,+1 个 BOS token)。
自动求导(Autograd)
训练神经网络需要梯度:对于模型中的每个参数,我们需要知道”如果我把这个数稍微往上调一点,损失是上升还是下降,变化多少?”。计算图有很多输入(模型参数和输入 token),但汇聚到单个标量输出:损失。反向传播从那个单一输出开始,沿着图向后工作,计算损失对每个输入的梯度。它依赖微积分的链式法则。
在生产中,PyTorch 等库会自动处理这些。这里,我们在一个名为 Value 的类中从头实现:
class Value:
__slots__ = ('data', 'grad', '_children', '_local_grads')
def __init__(self, data, children=(), local_grads=()):
self.data = data # 前向传播时计算的标量值
self.grad = 0 # 反向传播时计算的损失对该节点的导数
self._children = children # 计算图中该节点的子节点
self._local_grads = local_grads # 该节点对其子节点的局部导数
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def __pow__(self, other): return Value(self.data**other, (self,), (other * self.data**(other-1),))
def log(self): return Value(math.log(self.data), (self,), (1/self.data,))
def exp(self): return Value(math.exp(self.data), (self,), (math.exp(self.data),))
def relu(self): return Value(max(0, self.data), (self,), (float(self.data > 0),))
def __neg__(self): return self * -1
def __radd__(self, other): return self + other
def __sub__(self, other): return self + (-other)
def __rsub__(self, other): return other + (-self)
def __rmul__(self, other): return self * other
def __truediv__(self, other): return self * other**-1
def __rtruediv__(self, other): return other * self**-1
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v._children:
build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1
for v in reversed(topo):
for child, local_grad in zip(v._children, v._local_grads):
child.grad += local_grad * v.grad
简而言之,Value 包装单个标量数字(.data)并追踪它是如何计算的。把每个操作想象成一个小乐高积木:它接收一些输入,产生一个输出(前向传播),并且知道它的输出相对于每个输入会如何变化(局部梯度)。这就是 autograd 需要从每个块获得的全部信息。其他一切都只是链式法则,把块串在一起。
每当你用 Value 对象做数学运算(加、乘等),结果是一个新的 Value,它记住它的输入(_children)和该操作的局部导数(_local_grads)。例如,__mul__ 记录:
和
\[\frac{\partial(a \cdot b)}{\partial b} = a\]完整的乐高积木集合:
| 操作 | 前向 | 局部梯度 |
|---|---|---|
a + b |
\(a + b\) | \(\frac{\partial}{\partial a} = 1, \quad \frac{\partial}{\partial b} = 1\) |
a * b |
\(a \cdot b\) | \(\frac{\partial}{\partial a} = b, \quad \frac{\partial}{\partial b} = a\) |
a ** n |
\(a^n\) | \(\frac{\partial}{\partial a} = n \cdot a^{n-1}\) |
log(a) |
\(\ln(a)\) | \(\frac{\partial}{\partial a} = \frac{1}{a}\) |
exp(a) |
\(e^a\) | \(\frac{\partial}{\partial a} = e^a\) |
relu(a) |
\(\max(0, a)\) | \(\frac{\partial}{\partial a} = \mathbf{1}_{a > 0}\) |
backward() 方法以反向拓扑顺序遍历这个图(从损失开始,到参数结束),在每一步应用链式法则。如果损失是 \(L\),节点 \(v\) 有子节点 \(c\),局部梯度是 \(\frac{\partial v}{\partial c}\),那么:
如果你对微积分不太熟悉,这可能看起来有点吓人,但这实际上只是以直观的方式乘两个数字。一种理解方式是:”如果汽车的速度是自行车的两倍,自行车的速度是步行者的四倍,那么汽车的速度是步行者的 2 × 4 = 8 倍。”链式法则是一样的想法:你沿着路径乘以变化率。
我们通过在损失节点设置 self.grad = 1 来启动,因为 \(\frac{\partial L}{\partial L} = 1\):损失相对于自身的变化率显然是 1。从那里,链式法则只是沿着每条路径乘以局部梯度回到参数。
注意 +=(累加,不是赋值)。当一个值在图中多个地方使用(即图分支),梯度沿每个分支独立流回,必须相加。这是多变量链式法则的结果:如果 \(c\) 通过多条路径贡献到 \(L\),总导数是每条路径贡献的总和。
backward() 完成后,图中每个 Value 都有一个 .grad,包含 \(\frac{\partial L}{\partial v}\),告诉我们如果微调那个值,最终损失会如何变化。
参数(Parameters)
参数是模型的知识。它们是大量的浮点数(包装在 Value 中用于 autograd),一开始是随机的,在训练过程中被迭代优化。每个参数的确切作用在我们定义模型架构后会更有意义,但现在我们只需要初始化它们:
n_embd = 16 # 嵌入维度
n_head = 4 # 注意力头数量
n_layer = 1 # 层数
block_size = 16 # 最大序列长度
head_dim = n_embd // n_head # 每个头的维度
matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]
state_dict = {'wte': matrix(vocab_size, n_embd), 'wpe': matrix(block_size, n_embd), 'lm_head': matrix(vocab_size, n_embd)}
for i in range(n_layer):
state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd)
state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd)
params = [p for mat in state_dict.values() for row in mat for p in row]
print(f"num params: {len(params)}")
每个参数初始化为从高斯分布抽取的小随机数。state_dict 将它们组织成命名矩阵(借用 PyTorch 的术语):嵌入表、注意力权重、MLP 权重和最终输出投影。我们还将所有参数展平为单个列表 params,以便优化器稍后可以遍历它们。
在我们的微型模型中,这相当于 4,192 个参数。GPT-2 有 16 亿个,现代 LLM 有数千亿个。
架构(Architecture)
模型架构是一个无状态函数:它接收一个 token、一个位置、参数和之前位置的缓存键/值,返回 logits(分数),表示模型认为序列中下一个应该是什么 token。我们遵循 GPT-2,做了少量简化:用 RMSNorm 代替 LayerNorm,没有偏置项,用 ReLU 代替 GeLU。
首先,三个小辅助函数:
def linear(x, w):
return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]
linear 是矩阵-向量乘法。它接收向量 x 和权重矩阵 w,为 w 的每行计算一个点积。这是神经网络的基本构建块:学习到的线性变换。
def softmax(logits):
max_val = max(val.data for val in logits)
exps = [(val - max_val).exp() for val in logits]
total = sum(exps)
return [e / total for e in exps]
softmax 将原始分数向量(logits,范围从 \(-\infty\) 到 \(+\infty\))转换为概率分布:所有值最终在 \([0, 1]\) 并且总和为 1。我们先减去最大值以保持数值稳定性(数学上不改变结果,但防止 exp 溢出)。
def rmsnorm(x):
ms = sum(xi * xi for xi in x) / len(x)
scale = (ms + 1e-5) ** -0.5
return [xi * scale for xi in x]
rmsnorm(均方根归一化)重新缩放向量,使其值具有单位均方根。这防止激活在网络中流动时增长或收缩,稳定训练。它是原始 GPT-2 中 LayerNorm 的简化变体。
现在是模型本身:
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id] # token 嵌入
pos_emb = state_dict['wpe'][pos_id] # 位置嵌入
x = [t + p for t, p in zip(tok_emb, pos_emb)] # 联合 token 和位置嵌入
x = rmsnorm(x)
for li in range(n_layer):
# 1) 多头注意力块
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict[f'layer{li}.attn_wq'])
k = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
keys[li].append(k)
values[li].append(v)
x_attn = []
for h in range(n_head):
hs = h * head_dim
q_h = q[hs:hs+head_dim]
k_h = [ki[hs:hs+head_dim] for ki in keys[li]]
v_h = [vi[hs:hs+head_dim] for vi in values[li]]
attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5 for t in range(len(k_h))]
attn_weights = softmax(attn_logits)
head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)]
x_attn.extend(head_out)
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)]
# 2) MLP 块
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)]
logits = linear(x, state_dict['lm_head'])
return logits
这个函数在特定时间位置(pos_id)处理一个 token(id 为 token_id),以及由 keys 和 values 中的激活总结的之前迭代的一些上下文,称为 KV Cache。以下是逐步发生的事情:
嵌入(Embeddings)。 神经网络不能直接处理像 5 这样的原始 token id。它只能处理向量(数字列表)。所以我们为每个可能的 token 关联一个学习到的向量,并将其作为神经签名输入。token id 和位置 id 各自从它们的嵌入表(wte 和 wpe)查找一行。这两个向量相加,给模型一个既编码 token 是什么又编码它在序列中位置的表达。现代 LLM 通常跳过位置嵌入,引入其他基于相对位置的方案,如 RoPE。
注意力块(Attention Block)。 当前 token 被投影到三个向量:查询(Q)、键(K)和值(V)。直觉上,查询说”我在找什么?”,键说”我包含什么?”,值说”如果被选中我提供什么?”。例如,在名字”emma”中,当模型在第二个”m”处尝试预测接下来是什么,它可能学习到一个查询如”最近出现了什么元音?”。早期的”e”会有一个匹配这个查询的键,所以它获得高注意力权重,它的值(关于是元音的信息)流入当前位置。键和值被追加到 KV 缓存,所以之前的位置可用。每个注意力头计算其查询与所有缓存键之间的点积(按 \(\sqrt{d_{head}}\) 缩放),应用 softmax 获得注意力权重,取缓存值的加权和。所有头的输出被拼接并通过 attn_wo 投影。值得强调的是,注意力块是一个 token 在位置 t 得以”看”过去 0..t-1 位置 token 的确切且唯一的地方。注意力是一种 token 通信机制。
MLP 块。 MLP 是”多层感知机”的缩写,它是一个两层前馈网络:投影到 4 倍嵌入维度,应用 ReLU,投影回来。这是模型在每个位置做大部分”思考”的地方。与注意力不同,这个计算完全在时间 t 局部进行。Transformer 将通信(注意力)与计算(MLP)穿插在一起。
残差连接(Residual Connections)。 注意力和 MLP 块都将它们的输出加回到输入(x = [a + b for ...])。这让梯度直接流过网络,使更深的模型可训练。
输出(Output)。 最终隐藏状态通过 lm_head 投影到词汇表大小,为词汇表中的每个 token 产生一个 logit。在我们的例子中,只有 27 个数字。更高的 logit = 模型认为对应的 token 更可能接下来出现。
训练循环(Training Loop)
现在我们把所有东西连起来。训练循环重复: (1) 选择一个文档,(2) 在其 token 上运行模型前向传播,(3) 计算损失,(4) 反向传播获得梯度,(5) 更新参数。
# 创建 Adam,受祝福的优化器及其缓冲区
learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8
m = [0.0] * len(params) # 一阶矩缓冲区
v = [0.0] * len(params) # 二阶矩缓冲区
# 顺序重复
num_steps = 1000 # 训练步数
for step in range(num_steps):
# 取单个文档,分词,两边用 BOS 特殊 token 包围
doc = docs[step % len(docs)]
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
n = min(block_size, len(tokens) - 1)
# 将 token 序列前向传播通过模型,一直构建计算图到损失
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
losses = []
for pos_id in range(n):
token_id, target_id = tokens[pos_id], tokens[pos_id + 1]
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # 文档序列上的最终平均损失
# 反向传播损失,计算对所有模型参数的梯度
loss.backward()
# Adam 优化器更新:根据相应梯度更新模型参数
lr_t = learning_rate * (1 - step / num_steps) # 线性学习率衰减
for i, p in enumerate(params):
m[i] = beta1 * m[i] + (1 - beta1) * p.grad
v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2
m_hat = m[i] / (1 - beta1 ** (step + 1))
v_hat = v[i] / (1 - beta2 ** (step + 1))
p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam)
p.grad = 0
print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")
在 1,000 步中,损失从约 3.3(在 27 个 token 中随机猜测:\(-\log(1/27) \approx 3.3\))下降到约 2.37。越低越好,最低可能是 0(完美预测),所以还有改进空间,但模型显然在学习名字的统计模式。
推理(Inference)
训练完成后,我们可以从模型采样新名字。参数被冻结,我们只需在循环中运行前向传播,将每个生成的 token 作为下一个输入反馈:
temperature = 0.5 # 在 (0, 1] 范围内,控制生成文本的"创造性",从低到高
print("\n--- inference (new, hallucinated names) ---")
for sample_idx in range(20):
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
token_id = BOS
sample = []
for pos_id in range(block_size):
logits = gpt(token_id, pos_id, keys, values)
probs = softmax([l / temperature for l in logits])
token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]
if token_id == BOS:
break
sample.append(uchars[token_id])
print(f"sample {sample_idx+1:2d}: {''.join(sample)}")
每个样本以 BOS token 开始,告诉模型”开始一个新名字”。模型产生 27 个 logits,我们转换为概率,根据这些概率随机采样一个 token。那个 token 被反馈作为下一个输入,我们重复直到模型产生 BOS(意味着”我完成了”)或我们达到最大序列长度。
temperature 参数控制随机性。在 softmax 之前,我们将 logits 除以 temperature。temperature 为 1.0 直接从模型学习的分布采样。较低的 temperature(如这里的 0.5)使分布更尖锐,使模型更保守,更可能选择它的首选。接近 0 的 temperature 会总是选择单个最可能的 token(贪婪解码)。较高的 temperature 使分布平坦,产生更多样但可能不太连贯的输出。
运行它
你只需要 Python(不需要 pip install,没有依赖):
脚本在我的 MacBook 上运行大约需要 1 分钟。你会看到每步打印的损失:
train.py
num docs: 32033
vocab size: 27
num params: 4192
step 1 / 1000 | loss 3.3660
step 2 / 1000 | loss 3.4243
step 3 / 1000 | loss 3.1778
...
step 999 / 1000 | loss 2.3812
step 1000 / 1000 | loss 2.3721
看着它从 ~3.3(随机)降到 ~2.37。这个数字越低,网络对序列中下一个 token 的预测就越好。
与生产级 LLM 的差距
microgpt 包含了训练和运行 GPT 的完整算法本质。但在它和生产级 LLM 如 ChatGPT 之间,有一长串变化。它们都不改变核心算法和整体布局,但它们是让它在大规模上真正工作的原因:
数据。 不是 32K 个短名字,生产模型在数万亿 token 的互联网文本上训练:网页、书籍、代码等。数据经过去重、质量过滤和跨领域精心混合。
分词器。 不是单个字符,生产模型使用子词分词器如 BPE(字节对编码),它学习将频繁共现的字符序列合并为单个 token。像”the”这样的常见词变成单个 token,罕见词被分解成片段。这产生了约 100K token 的词汇表,效率更高,因为模型在每个位置看到更多内容。
自动求导。 microgpt 在纯 Python 中操作标量 Value 对象。生产系统使用张量(大量多维数字数组)并在 GPU/TPU 上运行,每秒执行数十亿次浮点运算。PyTorch 等库处理张量上的 autograd,FlashAttention 等 CUDA 内核融合多个操作以提高速度。数学是相同的,只是对应于许多标量并行处理。
架构。 microgpt 有 4,192 个参数。GPT-4 级模型有数千亿个。总体上它是一个看起来非常相似的 Transformer 神经网络,只是更宽(10,000+ 的嵌入维度)和更深(100+ 层)。现代 LLM 还加入了更多类型的乐高积木并改变它们的顺序:例子包括 RoPE(旋转位置嵌入)代替学习位置嵌入,GQA(分组查询注意力)减少 KV 缓存大小,门控线性激活代替 ReLU,MoE(混合专家)层等。但注意力(通信)和 MLP(计算)在残差流上穿插的核心结构被很好保留。
训练。 不是每步一个文档,生产训练使用大批次(每步数百万 token)、梯度累积、混合精度(float16/bfloat16)和仔细的超参数调整。训练前沿模型需要数千个 GPU 运行数月。
优化。 microgpt 使用 Adam 和简单的线性学习率衰减,就这些。在大规模下,优化本身成为一门学科。模型以降低的精度(bfloat16 甚至 fp8)训练,跨大型 GPU 集群以提高效率,这引入了自己的数值挑战。优化器设置(学习率、权重衰减、beta 参数、预热计划、衰减计划)必须精确调整,正确的值取决于模型大小、批次大小和数据集组成。
后训练。 从训练中产生的基础模型(称为”预训练”模型)是文档补全器,不是聊天机器人。把它变成 ChatGPT 分两个阶段。首先,SFT(监督微调):你只需将文档换成精心策划的对话并继续训练。算法上没有任何变化。其次,RL(强化学习):模型生成响应,它们被评分(由人类、另一个”评判”模型或算法),模型从该反馈学习。本质上,模型仍在文档上训练,但这些文档现在由来自模型本身的 token 组成。
推理。 向数百万用户提供模型服务需要自己的工程栈:将请求批处理在一起、KV 缓存管理和分页(vLLM 等)、用于加速的推测解码、量化(以 int8/int4 而不是 float16 运行)以减少内存、以及跨多个 GPU 分布模型。本质上,我们仍在预测序列中的下一个 token,但有很多工程用于使其更快。
所有这些都是重要的工程和研究贡献,但如果你理解 microgpt,你就理解了算法本质。
FAQ
模型”理解”任何东西吗? 这是一个哲学问题,但从机制上讲:没有魔法发生。模型是一个大的数学函数,将输入 token 映射到下一个 token 的概率分布。在训练期间,参数被调整以使正确的下一个 token 更可能。这是否构成”理解”取决于你,但机制完全包含在上面的 200 行中。
为什么它有效? 模型有数千个可调参数,优化器每步微调它们一点点使损失下降。经过许多步,参数沉淀到捕获数据统计规律的值。对于名字,这意味着:名字通常以辅音开头,”qu”倾向于一起出现,名字很少有连续三个辅音等。模型不学习显式规则,它学习恰好反映它们的概率分布。
这和 ChatGPT 有什么关系? ChatGPT 是同样的核心循环(预测下一个 token、采样、重复),只是大规模放大,加上后训练使其具有对话性。当你与它聊天时,系统提示、你的消息和它的回复都只是序列中的 token。模型一次补全一个文档,和 microgpt 补全名字一样。
“幻觉”是怎么回事? 模型通过从概率分布采样生成 token。它没有真理的概念,它只知道给定训练数据哪些序列在统计上是合理的。microgpt “幻觉”一个像”karia”的名字,和 ChatGPT 自信地陈述一个错误事实是同样的现象。两者都是听起来合理但实际上不真实的补全。
为什么这么慢? microgpt 在纯 Python 中一次处理一个标量。单次训练步需要几秒。同样的数学在 GPU 上并行处理数百万标量,运行速度快几个数量级。
我可以让它生成更好的名字吗? 可以。训练更长时间(增加 num_steps),使模型更大(n_embd、n_layer、n_head),或使用更大的数据集。这些是大规模上也重要的同样旋钮。
如果我换数据集会怎样? 模型会学习数据中的任何模式。换成城市名称、宝可梦名称、英语单词或短诗的文件,模型会学习生成那些。其余代码不需要改变。
总结
microgpt 是理解 GPT 本质的绝佳学习资源:
- 核心算法极其简洁:数据 → 分词 → 嵌入 → 注意力 + MLP → 概率分布 → 采样
- 200 行代码涵盖完整流程:从自动求导到训练循环到推理
- 生产级 LLM 只是规模化:更多数据、更大模型、更好的工程,但本质相同
- 理解原理比使用框架更重要:这会让你在调试、优化和创新时更有底气
Karpathy 再次证明了他的教学天赋——把复杂的概念简化到最本质的形式。强烈建议读者亲自运行这个脚本,然后尝试修改:换数据集、调参数、增加层数。动手是理解的最佳方式。