本文翻译自 It’s all a blur,原载于 Hacker News。
如果你经常关注网络安全讨论,可能听过这样的说法:用模糊处理来打码是不安全的。理论上,模糊算法是可以逆转的。
但这让人有点困惑。模糊本质上是对像素值求平均。比如两个数的平均值是 3,你无法知道原来到底是 1 + 5 还是 3 + 3。两种情况的算术平均值都一样,原始信息似乎已经丢失了。那这个建议是不是错的?
嗯,既对也不对!确实可以通过确定性算法实现不可逆的模糊。但问题在于,很多情况下,模糊算法保留的信息远超肉眼可见——而且方式相当出人意料。今天我们就来构建一个基础模糊算法,然后把它彻底拆解。
最简单的模糊算法
如果模糊就是求平均,那最简单的算法就是移动平均(moving mean)。我们取一个固定大小的窗口,把每个像素值替换成其邻域内 n 个像素的算术平均值。当 n = 5 时,过程如下:
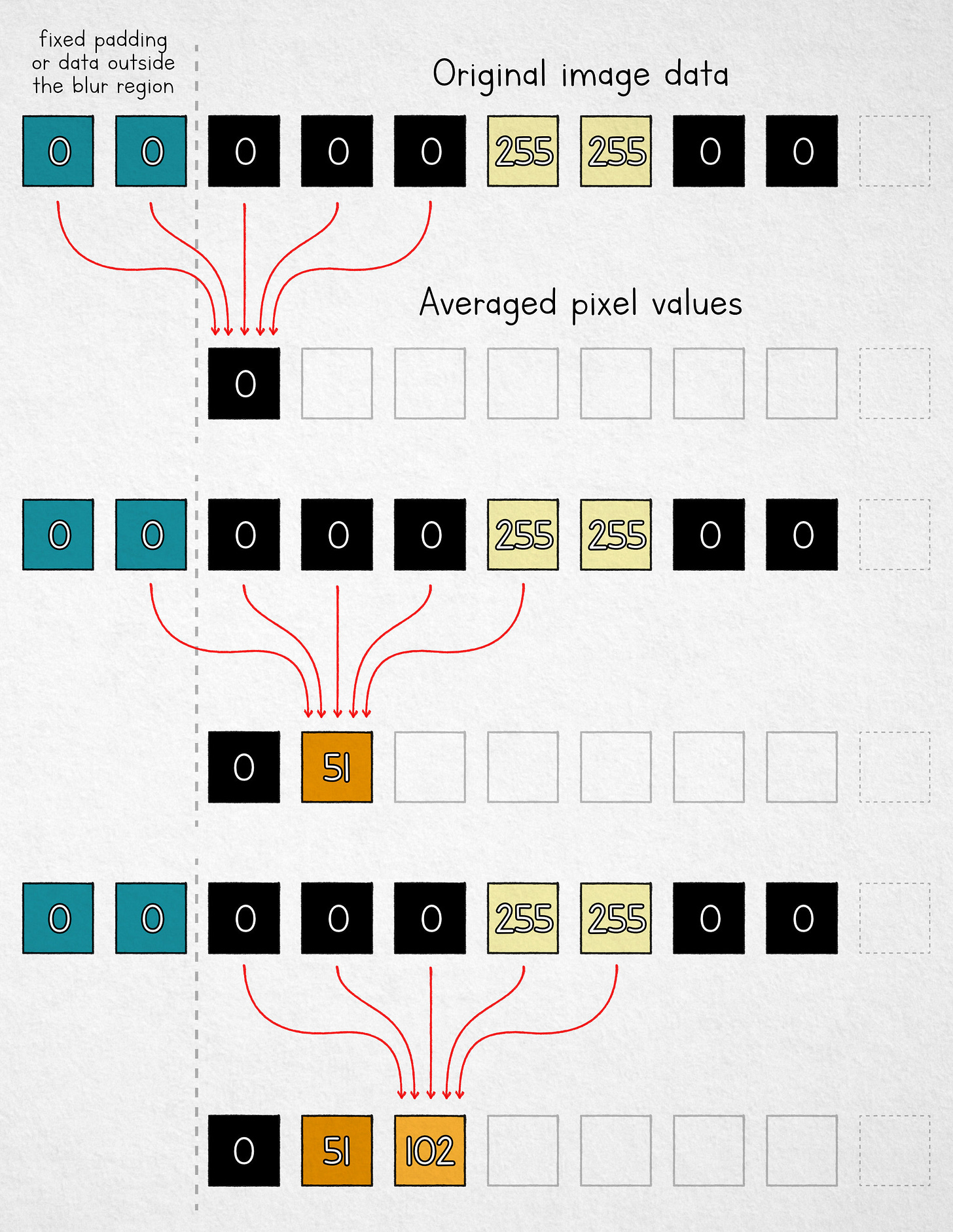
移动平均作为一种简单模糊算法
注意前两个单元格,我们在输入缓冲区中没有足够的像素。我们可以使用固定填充,从选择区域外”借用”一些可用像素,或者简单地在边界处平均较少的值。无论哪种方式,分析不会有太大变化。
逆向破解过程
假设我们已经完成了模糊处理,不再保留原始像素值。底层的图像还能重建吗?答案是可以,而且比想象中简单得多。我们不需要”去卷积”、”点扩散函数”、”核函数”这些大词,也不需要复杂的数学。
我们从左边界(x = 0)开始。回顾一下,我们计算第一个模糊像素时,是对原始图像中的以下像素求平均:
\[\text{blur}(0) = \frac{\text{img}(-2) + \text{img}(-1) + \text{img}(0) + \text{img}(1) + \text{img}(2)}{5}\]接下来,看看 x = 1 处的模糊像素,它的值是以下像素的平均值:
\[\text{blur}(1) = \frac{\text{img}(-1) + \text{img}(0) + \text{img}(1) + \text{img}(2) + \text{img}(3)}{5}\]我们可以通过两边乘以平均元素数量(5)轻松将这些平均值转换为求和:
\[\begin{align} 5 \cdot \text{blur}(0) &= \text{img}(-2) + \underline{\text{img}(-1) + \text{img}(0) + \text{img}(1) + \text{img}(2)} \\ 5 \cdot \text{blur}(1) &= \underline{\text{img}(-1) + \text{img}(0) + \text{img}(1) + \text{img}(2)} + \text{img}(3) \end{align}\]注意下划线标注的项在两个表达式中都重复出现。这意味着如果我们把两个表达式相减,最终得到:
\[5 \cdot \text{blur}(1) - 5 \cdot \text{blur}(0) = \text{img}(3) - \text{img}(-2)\]$\text{img}(-2)$ 的值对我们来说是已知的:它是算法使用的固定填充像素之一。我们把它简化为 c。我们也知道 $\text{blur}(0)$ 和 $\text{blur}(1)$ 的值:这些是可以在输出图像中找到的模糊像素。这意味着我们可以重新排列方程,恢复对应于 $\text{img}(3)$ 的原始输入像素:
\[\text{img}(3) = 5 \cdot (\text{blur}(1) - \text{blur}(0)) + c\]我们也可以对下一个像素应用同样的推理:
\[\text{img}(4) = 5 \cdot (\text{blur}(2) - \text{blur}(1)) + c\]改进的算法设计
到了这里,我们的五像素平均似乎碰壁了,但对 $\text{img}(3)$ 的了解让我们能够在稍后的 $\text{blur}(5) / \text{blur}(6)$ 对上重复同样的分析:
\[\begin{align} 5 \cdot \text{blur}(5) &= \text{img}(3) + \underline{\text{img}(4) + \text{img}(5) + \text{img}(6) + \text{img}(7)} \\ 5 \cdot \text{blur}(6) &= \underline{\text{img}(4) + \text{img}(5) + \text{img}(6) + \text{img}(7)} + \text{img}(8) \\ &\therefore \text{img}(8) = 5 \cdot (\text{blur}(6) - \text{blur}(5)) + \text{img}(3) \end{align}\]这又为我们赢得了另一个原始像素值 $\text{img}(8)$。从之前的步骤中,我们也知道 $\text{img}(4)$ 的值,所以我们可以用类似的方式找到 $\text{img}(9)$。这个过程可以持续进行以逐步重建更多像素,虽然我们最终会得到一些空隙。例如,按照上述计算,我们仍然不知道 $\text{img}(0)$ 或 $\text{img}(1)$ 的值。
这些空隙可以通过在图像缓冲区中相反方向的第二次传递来解决。不过,与其走那条路,我们也可以通过对平均算法的一个善意调整,使数学更加有序。
让我们的生活更轻松的修改是移动平均窗口,使其一端与计算值将存储的位置对齐:
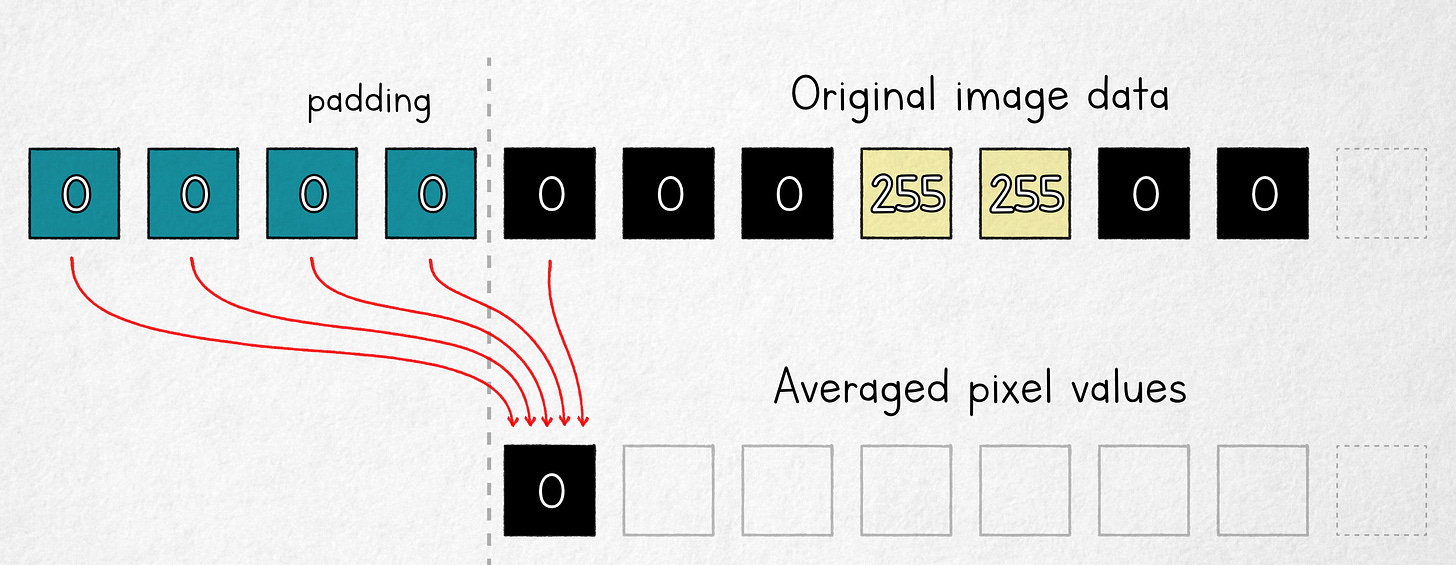
右对齐窗口的移动平均
在这个模型中,第一个输出值是四个固定填充像素(c)和一个原始图像像素的平均值。因此,在 n = 5 的情况下,可以计算底层像素值为:
\[\text{img}(0) = 5 \cdot \text{blur}(0) - 4 \cdot c\]如果我们知道 $\text{img}(0)$,我们现在拥有了组成 $\text{blur}(1)$ 的所有但一个值,所以我们可以找到 $\text{img}(1)$:
\[\text{img}(1) = 5 \cdot \text{blur}(1) - 3 \cdot c - \text{img}(0)\]这个过程可以迭代继续,重建整个图像——这次,没有任何不连续性,也无需第二次传递。
实验演示
在下图中,左侧面板展示了桑德罗·波提切利的《维纳斯的诞生》的细节;右侧面板是同一图像经过右对齐移动平均模糊算法处理的结果,平均窗口大小为 151 像素,仅在 x 方向上移动:

维纳斯,x 轴移动平均
现在,让我们拿这个模糊图像并尝试上述重建方法——计算机,增强!

维纳斯的重生
这相当令人印象深刻。由于中间模糊图像中平均值的 8 位量化,图像比以前更嘈杂。尽管如此,即使有大的平均窗口,精细的细节——包括单独的发丝——也能被恢复并容易辨认。
二维扩展
我们的模糊算法的问题是它只在 x 轴上平均像素值;这给出了运动模糊或相机抖动的外观。
我们开发的方法可以扩展到具有方形或十字形平均窗口的 2D 滤波器。不过,更方便的方法是在 x 轴上应用现有的 1D 滤波器,然后在 y 轴上进行互补传递。要撤销模糊,我们然后以相反顺序执行两次恢复传递。
不幸的是,无论我们采用 1D + 1D 还是真正的 2D 路线,我们都会发现每个像素的组合平均量导致底层值被如此严重地量化,以至于重建图像被噪声淹没:

从 1D + 1D 移动平均模糊的重建(x 后跟 y)
对抗性模糊设计
不过,如果我们想开发一个对抗性模糊滤波器,我们可以通过在计算的平均值中稍微更多地加权原始像素来解决这个问题。对于 x-then-y 变体,如果平均窗口大小为 W,当前像素偏置因子为 B,我们可以编写以下公式:
\[\text{blur}(n) = \frac{\text{img}(n - W) + \ldots + \text{img}(n - 1) + B \cdot \text{img}(n)}{W + B}\]这个滤波器仍然做它应该做的事情;以下是 W = 200 和 B = 30 的 x-then-y 模糊的输出:

维纳斯,重度 X-Y 模糊
当然,这肯定无法恢复了——计算机,增强!

维纳斯,从重度模糊中恢复
作为对怀疑者的概念证明,我们也可以制作一个同时在两个维度上运行的对抗性滤波器。以下是具有简单十字形窗口的 2D 滤波器后的重建:

从同时 2D 滤波器重建(W = 600×600,B = 10)
JPEG 压缩的惊人发现
值得注意的是,”隐藏”在模糊图像中的信息甚至能在保存为有损图像格式后存活。顶行显示了从以 95%、85% 和 75% 质量设置保存为 JPEG 的中间图像重建的图像:

从 JPEG 文件恢复(1D + 1D 滤波器,W = 200,B = 30)
底行显示了不太合理的 50% 及以下的质量设置;在那时,重建图像开始类似于抽象艺术。
关键要点
这篇文章揭示了几个令人震惊的事实:
-
模糊不等于加密:简单的移动平均模糊算法在数学上完全可以逆向推导出来,原始图像可以被精确重建。
-
信息保留超出想象:即使经过重度模糊处理,图像中仍然保留了足够的信息来恢复人脸、文字等敏感内容——包括发丝这样的精细细节。
-
JPEG 压缩也无济于事:令人惊讶的是,即使将模糊图像保存为 JPEG 格式(即使在 75% 这样的中等质量下),原始信息依然可以被提取出来。
- 安全的打码方式:如果你需要真正保护图像中的敏感信息,应该使用:
- 完全遮挡(黑色方块)
- 像素化(马赛克)配合足够大的块
- 完全删除/裁剪敏感区域
- 经过密码学验证的安全打码工具
- 防御性设计:文章还展示了如何设计”对抗性”模糊算法,通过给当前像素更高的权重来防止逆向工程。但即便如此,某些情况下仍可能被破解。
最后建议:永远不要依赖简单的模糊处理来保护敏感信息。无论看起来多么模糊,数学都可能让它重新变得清晰。